

STL - Vectors, Maps, Stack, Queue, Pairs & Some Leetcode Questions || 60 Days DSA Challange || #Day 1

Hello! I'm Mayank Aggarwal a B.Tech Student. As a dedicated tech enthusiast and blogger, I'm excited to welcome you to my corner of the internet. I am A backend Developer. I am Working on My DSA Skills. Now preparing for Interviews.
The C++ Standard Template Library (STL) is a powerful set of template classes and functions that provide general-purpose classes and algorithms with templates. It simplifies the programming process and allows developers to write efficient and reusable code. In this blog, we will delve into some essential components of the STL: Vectors, Maps, Stack, Queue, and Pairs.
Vectors
Certainly! Vectors are an essential part of the C++ Standard Template Library (STL) and provide dynamic arrays with various useful functions. Here's a detailed explanation of vectors in C++:
Overview:
Dynamic Array:
Vectors are dynamic arrays, meaning they can resize themselves automatically when elements are added or removed.
They provide a more flexible alternative to static arrays and eliminate the need for manual memory management.
Template Class:
- Vectors are implemented as a template class in C++, allowing them to store elements of any data type.
Declaration and Initialization:
#include <iostream>
#include <vector>
int main() {
// Declaration
std::vector<int> myVector;
// Initialization with values
std::vector<int> anotherVector = {1, 2, 3};
return 0;
}
Common Operations:
Pushing and Popping:
push_back(value): Adds an element to the end of the vector.pop_back(): Removes the last element from the vector.
myVector.push_back(4);
myVector.pop_back();
Accessing Elements:
- Elements can be accessed using indices like in arrays.
int element = myVector[1]; // Accessing the second element
Size and Capacity:
size(): Returns the number of elements in the vector.capacity(): Returns the current storage capacity of the vector.
std::cout << "Size: " << myVector.size() << std::endl;
std::cout << "Capacity: " << myVector.capacity() << std::endl;
Iterating Through Elements:
- Iterators provide a way to traverse the vector.
for (auto it = myVector.begin(); it != myVector.end(); ++it) {
// here we used auto but we can also use vector<int>::iterator *it
std::cout << *it << " ";
}
Clearing the Vector:
clear(): Removes all elements from the vector.
myVector.clear();
Advantages:
Dynamic Resizing:
- Vectors automatically manage memory, resizing themselves when the number of elements exceeds the current capacity.
Random Access:
- Elements can be accessed directly using indices, providing constant-time complexity for random access.
Useful Functions:
- Vectors come with various member functions and algorithms, making common tasks like sorting and searching more straightforward.
Compatible with Algorithms:
- Vectors work seamlessly with many algorithms from the
<algorithm>header, enabling powerful and concise code.
- Vectors work seamlessly with many algorithms from the
Example:
Let's consider a simple example where we use a vector to store and manipulate a list of integers:
#include <iostream>
#include <vector>
int main() {
std::vector<int> numbers = {3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5};
// Sorting the vector
std::sort(numbers.begin(), numbers.end());
// Printing the sorted vector
for (int num : numbers) {
std::cout << num << " ";
}
return 0;
}
In this example, we use the std::sort algorithm to sort the vector of numbers in ascending order.
Vector in Vector
Certainly! When you have a vector of vectors in C++, it is essentially a 2D array or a matrix. Each element of the outer vector is itself a vector, forming a collection of vectors. This structure is often used to represent a 2D grid or a matrix where each inner vector corresponds to a row or a column.
Here's a detailed explanation along with an example:
Declaration and Initialization:
#include <iostream>
#include <vector>
int main() {
// Declaration of a vector of vectors of integers
std::vector<std::vector<int>> matrix;
// Initialization with values
std::vector<std::vector<int>> grid = {
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
};
return 0;
}
Accessing Elements:
- Elements can be accessed using double indices, where the first index represents the row and the second index represents the column.
int element = grid[1][2]; // Accessing the element in the second row and third column
Common Operations:
Pushing and Popping:
- Elements can be added to the inner vectors using
push_backand removed usingpop_back.
- Elements can be added to the inner vectors using
grid[0].push_back(10); // Add 10 to the end of the first row
grid[1].pop_back(); // Remove the last element from the second row
Size and Capacity:
size()provides the number of rows, andsize()on an inner vector provides the number of columns.
std::cout << "Number of rows: " << grid.size() << std::endl;
std::cout << "Number of columns in the first row: " << grid[0].size() << std::endl;
Iterating Through Elements:
- Nested loops are used to iterate through all elements in the matrix.
for (const auto& row : grid) {
for (int element : row) {
std::cout << element << " ";
}
std::cout << std::endl;
}
Example:
Let's consider a scenario where we want to find the sum of each row in a matrix:
#include <iostream>
#include <vector>
int main() {
std::vector<std::vector<int>> matrix = {
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
};
// Finding the sum of each row
for (const auto& row : matrix) {
int rowSum = 0;
for (int element : row) {
rowSum += element;
}
std::cout << "Sum of row: " << rowSum << std::endl;
}
return 0;
}
In this example, we iterate through each row, calculating the sum of elements in each row of the matrix.
Using a vector of vectors is a flexible and efficient way to work with 2D data structures in C++. It allows you to perform various operations on rows and columns easily and is especially useful for representing grids, tables, or matrices in your programs.
- Comparison of
std::vectorandstd::vector<std::vector<T>>in a table format:
| Feature | std::vector | std::vector<std::vector<T>> |
| Dimensionality | Single-dimensional array | Two-dimensional array (matrix or grid) |
| Structure | Linear sequence of elements | Vector of vectors, forming rows and columns |
| Use Case | Simple lists, dynamic arrays | Matrices, grids, 2D structures |
| Access Pattern | Single indices | Double indices (row, column) |
| Example Declaration and Initialization | std::vector<int> myVector = {1, 2, 3}; | std::vector<std::vector<int>> matrix = {{1, 2, 3}, {4, 5, 6}, {7, 8, 9}}; |
Understanding these differences helps in choosing the appropriate data structure based on the requirements of your program. If you need a flat list of elements, a single-dimensional std::vector might be sufficient. If you are dealing with a 2D structure, such as a matrix, then a std::vector<std::vector<T>> is more suitable.
Certainly! Let's break down the concepts of pairs, vectors, vectors of vectors, and vectors of pairs, and then represent them in a table format.
2. Pairs:
In C++ (assuming you are referring to C++), a pair is a standard template library (STL) container that can hold two heterogeneous objects of any data type. It is defined in the <utility> header.
Here's a simple example:
#include <iostream>
#include <utility>
int main() {
std::pair<int, double> myPair = std::make_pair(5, 3.14);
std::cout << "First element: " << myPair.first << std::endl;
std::cout << "Second element: " << myPair.second << std::endl;
return 0;
}
Vector of Pairs:
A vector of pairs is a vector where each element is a pair.
Example:
#include <iostream>
#include <vector>
#include <utility>
int main() {
std::vector<std::pair<int, double>> pairVector = {{1, 2.5}, {3, 4.0}, {5, 6.3}};
for (const auto& pair : pairVector) {
std::cout << "(" << pair.first << ", " << pair.second << ") ";
}
return 0;
}
Vector vs Vector of Vectors vs Vector of Pairs :
| Container Type | Example Declaration | Example Initialization/Assignment |
| Vector | std::vector<int> myVector = {1, 2, 3, 4, 5}; | std::vector<int> myVector = {1, 2, 3, 4, 5}; |
| Vector of Vectors | std::vector<std::vector<int>> matrix = {{1, 2, 3}, {4, 5, 6}, {7, 8, 9}}; | std::vector<std::vector<int>> matrix = {{1, 2, 3}, {4, 5, 6}, {7, 8, 9}}; |
| Vector of Pairs | std::vector<std::pair<int, double>> pairVector = {{1, 2.5}, {3, 4.0}, {5, 6.3}}; | std::vector<std::pair<int, double>> pairVector = {{1, 2.5}, {3, 4.0}, {5, 6.3}}; |
This table summarizes the declaration and initialization/assignment of vectors, vectors of vectors, and vectors of pairs in C++.
Certainly! Maps in C++ are associative containers that store key-value pairs. They provide a way to associate a unique key with a corresponding value, allowing for efficient retrieval and manipulation of data. Here's an explanation along with a simple code example:
Overview:
Key-Value Pairs:
Maps store elements as key-value pairs, where each key is unique within the map.
The keys are used to efficiently search for and access corresponding values.
Ordered by Key:
Maps are typically implemented as binary search trees or hash tables, providing logarithmic time complexity for most operations.
Elements in a map are ordered by their keys.
Declaration and Initialization:
#include <iostream>
#include <map>
int main() {
// Declaration of a map with int keys and string values
std::map<int, std::string> myMap;
// Initialization with values
myMap[1] = "One";
myMap[2] = "Two";
myMap[3] = "Three";
return 0;
}
Common Operations:
Insertion:
- Elements can be inserted into a map using the
insertfunction or the square bracket notation.
- Elements can be inserted into a map using the
// Using insert
myMap.insert(std::make_pair(4, "Four"));
// Using square bracket notation
myMap[5] = "Five";
Accessing Elements:
- Elements are accessed using keys.
std::string value = myMap[2]; // Accessing the value associated with key 2
Iteration:
- Iterators can be used to traverse through all elements in the map.
for (auto it = myMap.begin(); it != myMap.end(); ++it) {
std::cout << "Key: " << it->first << ", Value: " << it->second << std::endl;
}
Finding Elements:
- The
findfunction is useful for searching for a specific key.
- The
auto found = myMap.find(3);
if (found != myMap.end()) {
std::cout << "Key 3 found. Value: " << found->second << std::endl;
} else {
std::cout << "Key 3 not found." << std::endl;
}
Size and Empty:
size()returns the number of elements, andempty()checks if the map is empty.
std::cout << "Size: " << myMap.size() << std::endl;
std::cout << "Is empty: " << (myMap.empty() ? "Yes" : "No") << std::endl;
Certainly! Let's delve into C++ maps, including both std::map (ordered map) and std::unordered_map (unordered map), and provide a comparison at the end.
std::map (Ordered Map):
Overview:
std::mapis an ordered associative container that stores elements as key-value pairs.Elements are ordered based on the keys.
Declaration and Initialization:
#include <iostream>
#include <map>
int main() {
// Declaration of an ordered map with int keys and string values
std::map<int, std::string> orderedMap;
// Initialization with values
orderedMap[1] = "One";
orderedMap[2] = "Two";
orderedMap[3] = "Three";
return 0;
}
- Common Operations:
// Insertion
orderedMap.insert(std::make_pair(4, "Four"));
// Accessing Elements
std::string value = orderedMap[2];
// Iteration
for (auto it = orderedMap.begin(); it != orderedMap.end(); ++it) {
std::cout << "Key: " << it->first << ", Value: " << it->second << std::endl;
}
// Finding Elements
auto found = orderedMap.find(3);
if (found != orderedMap.end()) {
std::cout << "Key 3 found. Value: " << found->second << std::endl;
}
std::unordered_map (Unordered Map):
Overview:
std::unordered_mapis an unordered associative container that stores elements as key-value pairs.Elements are unordered, and access time is constant on average.
Declaration and Initialization:
#include <iostream>
#include <unordered_map>
int main() {
// Declaration of an unordered map with int keys and string values
std::unordered_map<int, std::string> unorderedMap;
// Initialization with values
unorderedMap[1] = "One";
unorderedMap[2] = "Two";
unorderedMap[3] = "Three";
return 0;
}
- Common Operations:
// Insertion
unorderedMap.insert(std::make_pair(4, "Four"));
// Accessing Elements
std::string value = unorderedMap[2];
// Iteration
for (const auto& entry : unorderedMap) {
std::cout << "Key: " << entry.first << ", Value: " << entry.second << std::endl;
}
// Finding Elements
auto found = unorderedMap.find(3);
if (found != unorderedMap.end()) {
std::cout << "Key 3 found. Value: " << found->second << std::endl;
}
Comparison:
| Feature | std::map | std::unordered_map |
| Ordering of Elements | Ordered | Unordered |
| Access Time Complexity | Logarithmic (O(log n)) | Constant on average (O(1)) |
| Use Case | When order matters, e.g., sorting | When quick access is needed |
| Example Declaration | std::map<int, std::string> myMap; | std::unordered_map<int, std::string> myUnorderedMap; |
Example:
Let's consider a scenario where we use both an ordered map and an unordered map to store and retrieve information about cities and their populations:
#include <iostream>
#include <map>
#include <unordered_map>
int main() {
// Ordered Map
std::map<std::string, int> orderedCityPopulation;
orderedCityPopulation["New York"] = 8537673;
orderedCityPopulation["Los Angeles"] = 3976322;
orderedCityPopulation["Chicago"] = 2716000;
// Unordered Map
std::unordered_map<std::string, int> unorderedCityPopulation;
unorderedCityPopulation["New York"] = 8537673;
unorderedCityPopulation["Los Angeles"] = 3976322;
unorderedCityPopulation["Chicago"] = 2716000;
return 0;
}
In this example, we use both an ordered map and an unordered map to store city-population data. The ordered map maintains the order of cities based on their names, while the unordered map provides quick access to population data with constant time complexity.
Maps in C++ are powerful data structures that provide efficient key-based access to values. They are widely used in scenarios where you need to quickly look up information based on a unique key.
Stack:
Overview:
A stack is a Last In First Out (LIFO) data structure, where the last element added is the first to be removed.
Elements are added and removed from the same end, typically referred to as the top of the stack.
Declaration and Initialization:
#include <iostream> #include <stack> int main() { // Declaration of a stack of integers std::stack<int> myStack; // Pushing elements onto the stack myStack.push(1); myStack.push(2); myStack.push(3); return 0; }Common Operations:
// Popping elements from the stack while (!myStack.empty()) { std::cout << myStack.top() << " "; myStack.pop(); }
Queue:
Overview:
A queue is a First In First Out (FIFO) data structure, where the first element added is the first to be removed.
Elements are added at the back (enqueue) and removed from the front (dequeue) of the queue.
Declaration and Initialization:
#include <iostream> #include <queue> int main() { // Declaration of a queue of integers std::queue<int> myQueue; // Enqueuing elements into the queue myQueue.push(1); myQueue.push(2); myQueue.push(3); return 0; }Common Operations:
// Dequeuing elements from the queue while (!myQueue.empty()) { std::cout << myQueue.front() << " "; myQueue.pop(); }
Example:
Let's consider a scenario where we use a stack and a queue to process a list of tasks. The tasks are added to the stack and dequeued from the queue, demonstrating the LIFO and FIFO behaviors, respectively:
#include <iostream>
#include <stack>
#include <queue>
int main() {
// Stack Example
std::stack<int> taskStack;
taskStack.push(1);
taskStack.push(2);
taskStack.push(3);
std::cout << "Stack (LIFO) Order: ";
while (!taskStack.empty()) {
std::cout << taskStack.top() << " ";
taskStack.pop();
}
std::cout << std::endl;
// Queue Example
std::queue<int> taskQueue;
taskQueue.push(1);
taskQueue.push(2);
taskQueue.push(3);
std::cout << "Queue (FIFO) Order: ";
while (!taskQueue.empty()) {
std::cout << taskQueue.front() << " ";
taskQueue.pop();
}
std::cout << std::endl;
return 0;
}
In this example, we use a stack to process tasks in a Last In First Out manner and a queue to process tasks in a First In First Out manner.
Both stacks and queues have important applications in computer science and are widely used in various algorithms and data structures. Understanding when to use each depends on the specific requirements of your problem.
Understanding DP
- Eg: Fibonacci Series
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5+10;
// 8112358
// func(n) > nth fib number
int fib(int n){
if(n == 0) return 0;
if(n == 1) return 1;
return fib(n-1) + fib(n-2);
}
int main(){
int n;
cin >> n;
cout << fib(n);
}
This is the Fibonacci code with recursion only. The code is correct but there is a problem of Time Complexity. As we can see every time the call has exponential Numbers. As you can see in the figure below.
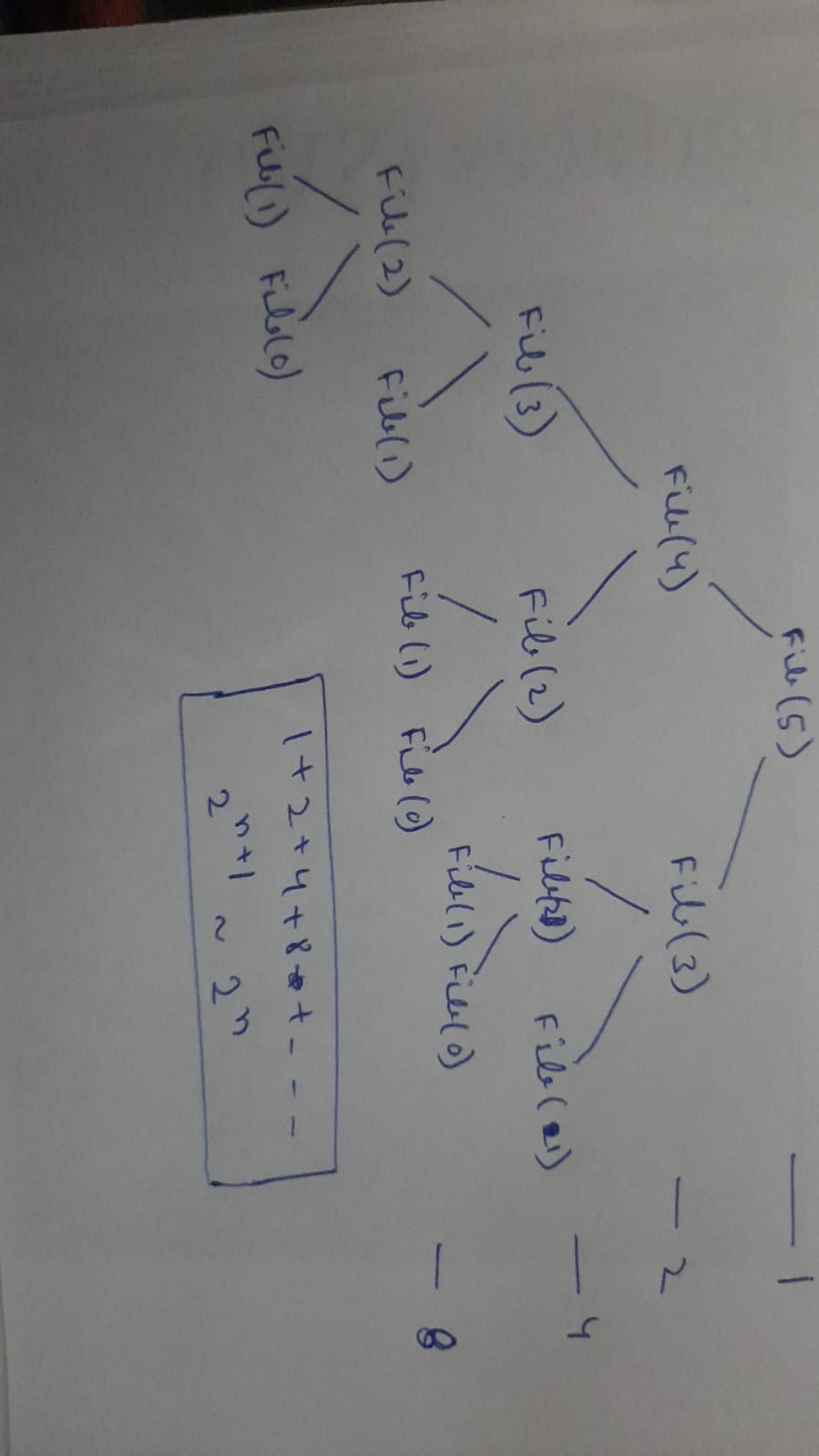
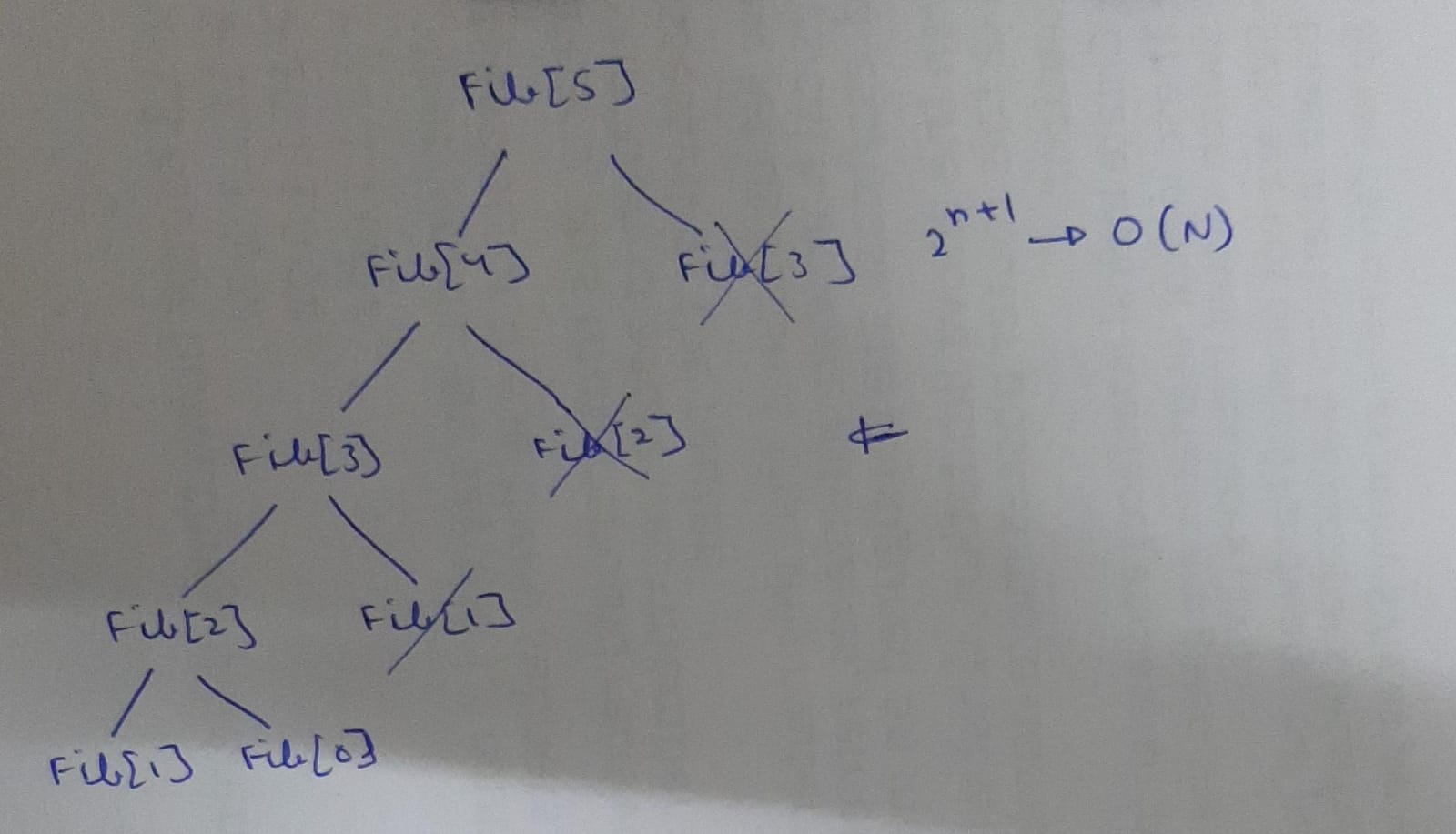
So this can be reduced by DP. Most simply, you can say dp is nothing but recursion but it Stores calculated values and uses it to decrease the complexity.
Solving LeetCode Questions
78. SubSets (recursion)
class Solution {
public:
void generate(vector<int> &subset,int i,vector<int>& nums,vector<vector<int>>& ans){
if(i==nums.size()){
ans.push_back(subset);
return;
}
// not including the number
generate(subset,i+1,nums,ans);
// including the number
subset.push_back(nums[i]);
generate(subset,i+1,nums,ans);
subset.pop_back();
}
vector<vector<int>> subsets(vector<int>& nums) {
vector<int> empty;
int i=0;
vector<vector<int>> ans;
generate(empty,i,nums,ans);
return ans;
}
};
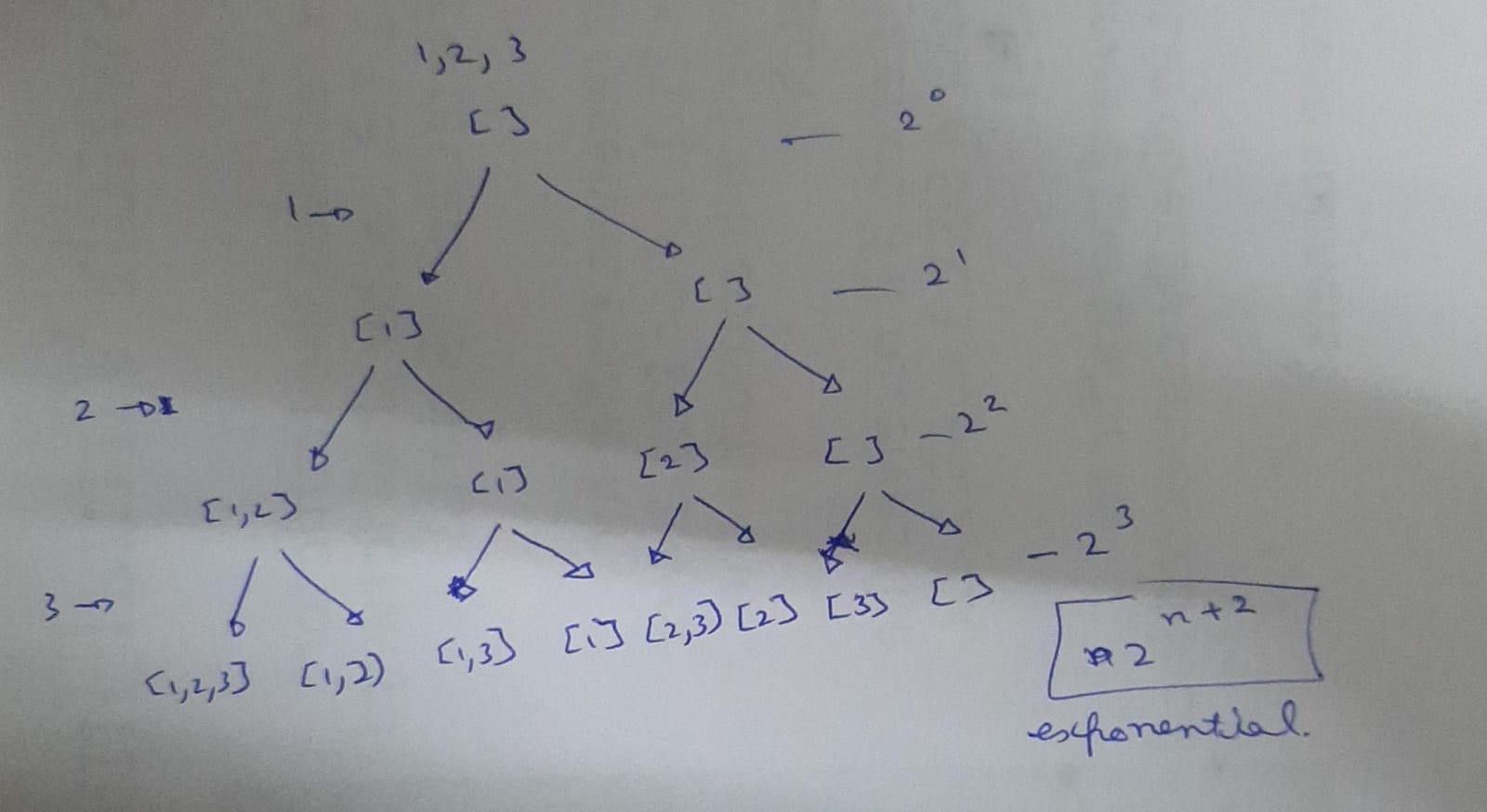
As you can see There are only two cases in the question either we include a number or we will not include the number. As Shown Below:-
70. Climbing Stairs
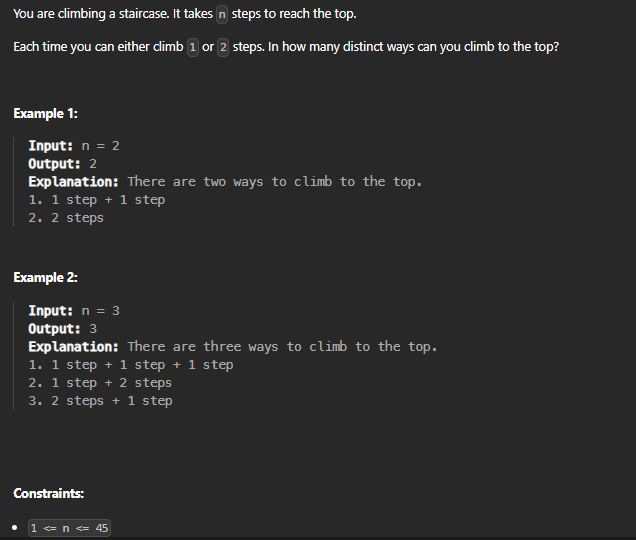
class Solution {
public:
int climbStairs(int n) {
if (n == 0 || n == 1) {
return 1;
}
int prev = 1, curr = 1;
for (int i = 2; i <= n; i++) {
int temp = curr;
curr = prev + curr;
prev = temp;
}
return curr;
}
};
This question is very similar to the Fibonacci series. As we have only two cases we can take 1 or 2 steps at a time. With the base Case for n 0,1 to be 1.
Approach 1: Recursion ❌ TLE ❌
Explanation: The recursive solution uses the concept of Fibonacci numbers to solve the problem. It calculates the number of ways to climb the stairs by recursively calling the climbStairs function for (n-1) and (n-2) steps. However, this solution has exponential time complexity (O(2^n)) due to redundant calculations.
Approach 2: Memoization
Explanation: The memoization solution improves the recursive solution by introducing memoization, which avoids redundant calculations. We use an unordered map (memo) to store the already computed results for each step n. Before making a recursive call, we check if the result for the given n exists in the memo. If it does, we return the stored value; otherwise, we compute the result recursively and store it in the memo for future reference.
198. House Robber
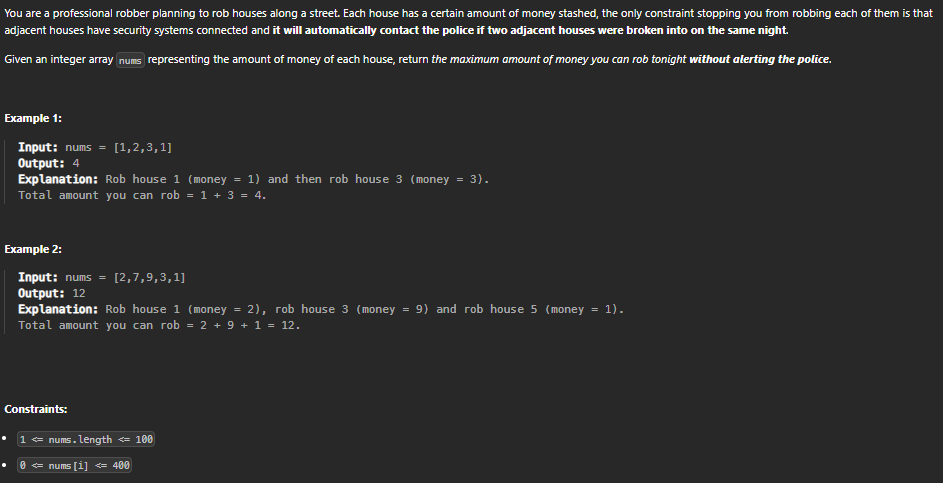
int memo[400];
class Solution {
public:
// tle
// int helper_recursive_topdown(vector<int>& nums,int i){
// if(i<0){
// return 0;
// }
// return max(helper_recursive_topdown(nums,i-2)+nums[i],helper_recursive_topdown(nums,i-1));
// }
int helper_recursive_memotd(vector<int>& nums,int i){
if(i<0){
return 0;
}
if(memo[i]>=0){
return memo[i];
}
int result = max(helper_recursive_memotd(nums,i-2)+nums[i],helper_recursive_memotd(nums,i-1));
memo[i]=result;
return result;
}
int rob(vector<int>& nums) {
memset(memo,-1,sizeof(memo));
// return helper_recursive_topdown(nums,nums.size()-1);
return helper_recursive_memotd(nums,nums.size()-1);
}
};
Approach
We assign two variables ‘prevFirst' and ‘prevSecond’, Where ‘prevFirst is the cumulative sum till (’INDEX' - 1)th elements and ‘prevSecond’ is the cumulative sum till ('INDEX' - 2)th elements.
Consider two options to either include or exclude the ‘CURR’ element, i.e. ‘ARR[INDEX]’ in our subsequence, and we have two options:
Including the ‘CURR’ element, optionA = ‘prevSecond’ + ‘ARR[INDEX]’
Excluding the ‘CURR’ element, optionB = ‘prevFirst’.
Return max( optionA, optionB).
Complexity
- Time complexity:
O(N), Where ‘N’ is the number of elements in the given array/list.
Since we iterate through the given array/list resulting in total ‘N’ iterations, so the overall time complexity will be O(N).
- Space complexity:
Since we are only using two variables to store the result, So, overall space complexity will be O(1).
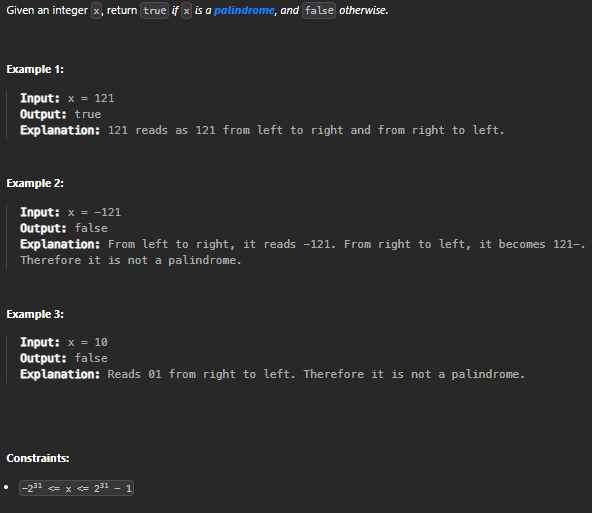
class Solution {
public:
bool isPalindrome(int x) {
if(x<0){
return false;
}
long long reversed = 0;
long long temp = x;
while (temp != 0) {
int digit = temp % 10;
reversed = reversed * 10 + digit;
temp /= 10;
}
return (reversed == x);
}
};
Explanation:
We begin by performing an initial check. If the input number
xis negative, it cannot be a palindrome since palindromes are typically defined for positive numbers. In such cases, we immediately returnfalse.We initialize two variables:
reversed: This variable will store the reversed value of the numberx.temp: This variable is a temporary placeholder to manipulate the input number without modifying the original value.
We enter a loop that continues until
tempbecomes zero:Inside the loop, we extract the last digit of
tempusing the modulo operator%and store it in thedigitvariable.To reverse the number, we multiply the current value of
reversedby 10 and add the extracteddigit.We then divide
tempby 10 to remove the last digit and move on to the next iteration.
Once the loop is completed, we have reversed the entire number. Now, we compare the reversed value
reversedwith the original input valuex.If they are equal, it means the number is a palindrome, so we return
true.If they are not equal, it means the number is not a palindrome, so we return
false.
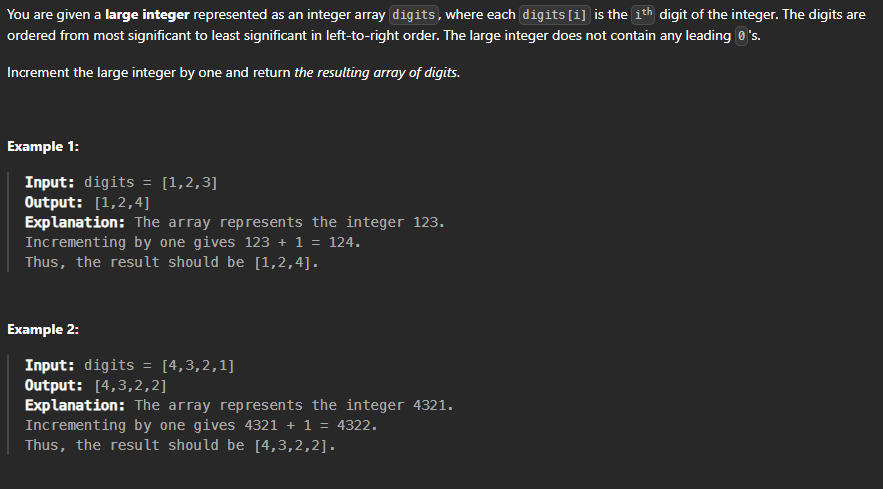
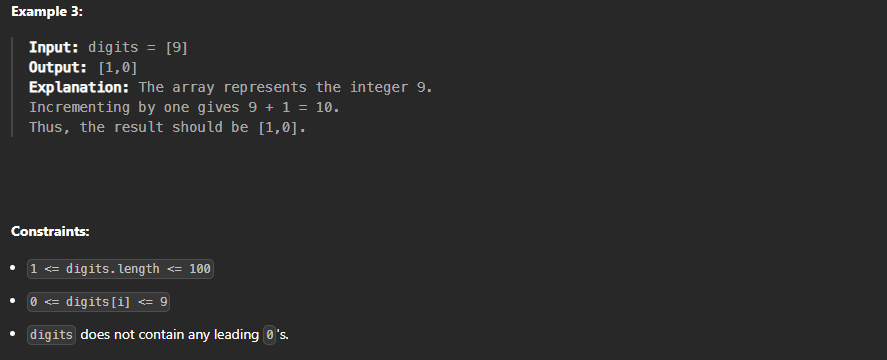
class Solution {
public:
vector<int> plusOne(vector<int>& v) {
int n = v.size();
for(int i = n-1; i >= 0; i--){
if(i == n-1)
v[i]++;
if(v[i] == 10){
v[i] = 0;
if(i != 0){
v[i-1]++;
}
else{
v.push_back(0);
v[i] = 1;
}
}
}
return v;
}
};
Approach
First, we increment the first digit (last element) by 1, if it becomes 10 we make it 0 and add 1 to the second digit.. until the last digit (first element), if it becomes 10 we make it 1 and push_back a leading zero.
Complexity
- Time complexity:
O(n)
Thank you reading Whole Blog . If you get any knowledge from this blog than make sure to like and follow.




